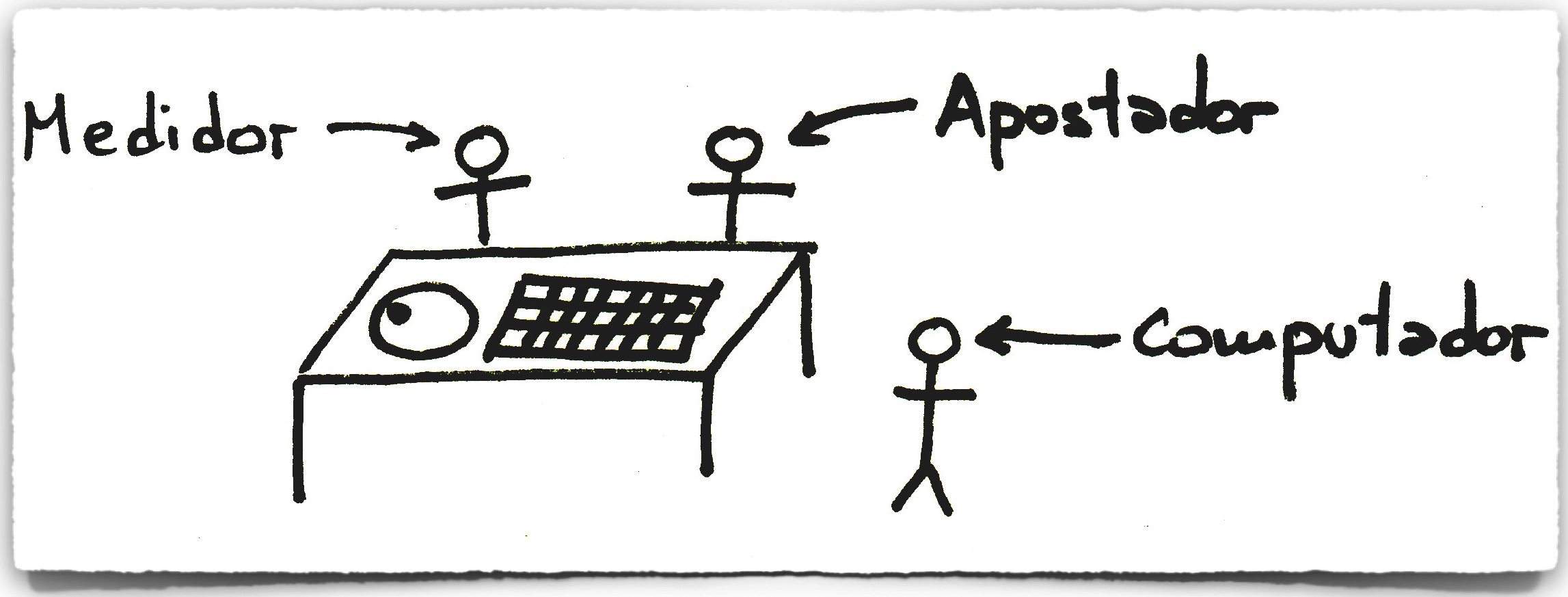
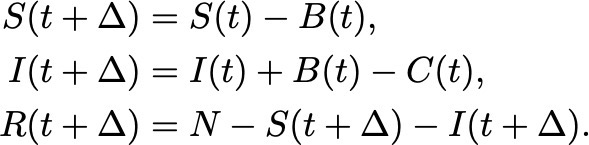En esta escena de la película El lobo de Wall Street, dirigida por Martin Scorsese (uno de los grandes directores de la historia del cine), Matthew McConaughey habla la “fugacidad” de la bolsa de valores. Llamativamente, la lírica de la canción “Money“, de Pink Floyd (del disco The Dark Side of the Moon, y que forma parte de la playlist de la materia), tiene la memorable frase “Money, it’s a gas“. Y aparentemente ninguna de estas frases es simplemente una licencia poética. En muchos sentidos hay conexiones profundas entre la mecánica estadística y el modelado de los mercados bursátiles, que en algunos casos se remontan hasta los inicios de la teoría.
Los que tengan curiosidad sobre cómo se usan herramientas de mecánica estadística para el estudio de economía y finanzas pueden mirar este muy buen review:
que fue publicado en Reviews of Modern Physics en 2009. El artículo es introductorio y explica varios de los conceptos que se usan comúnmente en el área de econofísica, incluyendo modelos estocásticos (como los modelos de camino al azar que vimos en clase), cómo se usa el ensamble canónico (o de Gibbs) y el ensamble gran canónico, los vínculos asociados a la “conservación del dinero”, o los vínculos que se usan en sistemas más realistas en los que pueden existir deudas y cómo esto resulta en diferentes equilibrios estadísticos. En particular, la Sección I, y la Sección II desde la subsección A hasta la C, se leen fácilmente, y usan muchos de los conceptos que introdujimos hasta ahora en la materia.
En las secciones II.B y II.C, los autores reemplazan el vínculo sobre la energía que usamos al derivar los ensambles, por un vínculo sobre el dinero total circulante. Si asumimos que el dinero total se conserva, la distribución de probabilidad de equilibrio para el dinero está dada por la distribución de Boltzmann-Gibbs,
![]()
donde m es la cantidad de dinero, y Tm es la “temperatura estadística” del sistema (es decir, el multiplicador de Lagrange). Esta cantidad (Tm) es igual al dinero medio disponible por persona. Noten que esta expresión para la probabilidad es formalmente igual a la obtenida en el ensamble canónico. Excepto por casos con ingresos extremadamente grandes (que deben ser modelados con otra distrubución de probabilidad, la distribución de Pareto), la distribución de Boltzmann-Gibbs está en buen acuerdo con los datos de muchos países. A modo de ejemplo, el review compara este resultado con la probabilidad acumulada en función de los ingresos de los individuos usando datos de la oficina de impuestos de los Estados Unidos.
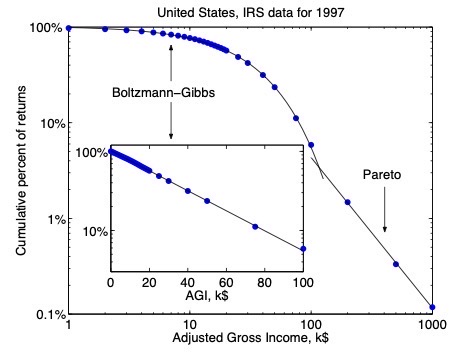
En esta figura los puntos azules son datos (porcentaje acumulado de casos en función de los ingresos brutos ajustados de cada contribuyente), y la linea negra de la izquierda corresponde a la distribución de Boltzmann-Gibbs (o la distribución canónica), seguida por la distribución de probabilidad de Pareto.
Este artículo tiene también un hallazgo interesante sobre la visión amplia que tenía Boltzmann de la física, que más de 100 años atrás vislumbró la aplicabilidad de la mecánica estadística tanto en física como en otras áreas muy diversas del conocimiento (una visión que se cumplió con creces). En 1905 Boltzmann, hablando sobre la generalización y formalización de la mecánica estadística realizada por Gibbs, escribió:
“Esto abre una perspectiva amplia, si no pensamos solamente en objetos mecánicos. Consideremos aplicar este método a la estadística de seres vivos, de la sociedad, en sociología, etc.”
Boltzmann tomó algunas ideas de estadística que ya se aplicaban en su época en el estudio de la sociedad para construir su teoría de los gases diluidos. Así que su propuesta de aplicar la incipiente mecánica estadística en estudios de la sociedad y en sociología podría resultar esperable. Hoy esta aplicación en particular recibe el nombre de sociofísica; el grupo de Pablo Balenzuela (@polbalen) trabaja en estos temas en el Departamento de Física. Y la famosa novela de ciencia ficción “Fundación“, de Isaac Asimov, también juega con la idea de aplicar la teoría de gases diluidos en las ciencias sociales para predecir el posible desarrollo de una sociedad.
Las aplicaciones actuales de la mecánica estadística en biología, economía, y otras ciencias pueden resultar aún más inesperadas. Los que quieran mirar un ejemplo más reciente de aplicaciones en economía pueden leer este artículo en Nature Communications sobre eventos extremos en sistemas macroeconómicos.