Stanislaw Lem fue un escritor polaco, autor de Solaris. El libro fue la base para el guión de la película Solaris (1972) dirigida por Andrei Tarkovsky (no estoy hablando de la remake de Hollywood). En Solaris, Lem imagina el oceano de un planeta que desarrolla en forma espontánea su propia conciencia (con un vínculo con un tema que veremos en el próximo posteo). Pero las novelas y cuentos de Stanislaw Lem tienen otros vínculos interesantes con la termodinámica y la mecánica estadística.
En Ciberíada Lem escribe cuentos breves sobre las aventuras de dos constructores, Trurl y Clapaucio. Ambos tienen poderes y capacidad de construcción sobrehumanos, y fueron ilustrados, en la edición original de Ciberíada, por Daniel Mróz, un artista polaco responsable de la ilustración de otros libros y novelas de Lem.
En una de las historias de Ciberíada, ambos son capturados por un pirata con un doctorado y sediento de información. Para escapar, Trurl y Clapaucio construyen un demonio del segundo tipo (un demonio del primer tipo, para Lem, es un demonio de Maxwell, considerado una trivialidad por Trurl y Clapaucio). El demonio de Lem puede observar todas las moléculas de un gas en cada microestado posible, y extraer información de sus configuraciones. Al fin y al cabo, siendo todos los microestados posibles, algunos microestados pueden corresponder a ordenamientos de las moléculas que revelen leyes fundamentales o secretos insondables del universo, ¿no? Esto es nada más y nada menos que le versión gaseosa de La Biblioteca de Babel de Borges.
“Si primero jura solemnemente, de arriba abajo y cruzando su corazón, que nos dejará ir, le daremos información, información sobre información infinita, es decir, le haremos su propio Demonio de Segundo Tipo, que es mágico y termodinámico, no-clásico y estocástico, y de cualquier viejo barril o estornudo extraerá información para usted sobre todo lo que fue, es, puede ser o será. ¡Y no hay demonio más allá de este Demonio, porque es del Segundo Tipo, y si lo quiere, dígalo ahora!“
Stanislaw Lem, Ciberíada (1965)
Pero, ¿qué es un demonio de Maxwell, o el despreciado demonio del primer tipo de Lem? Imaginemos un gas en un recinto, separado por un tabique. En el tabique agregamos una compuerta con un resorte, como se muestra en la siguiente figura:
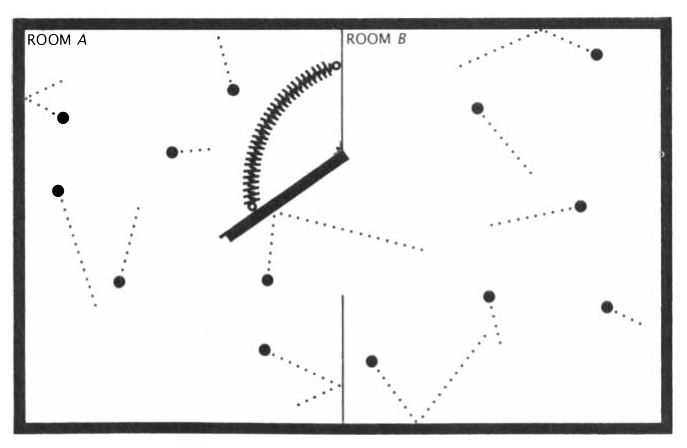
En 1867, James Clerk Maxwell imaginó un demonio que podía conocer el estado de cada una de las partículas en este gas. Este demonio es puesto a controlar la compuerta de la figura. Cada vez que una molécula del lado B se acerca a la compuerta, el demonio observa su energía cinética. Si es grande, el demonio cierra la compuerta. Pero si su energía cinética es pequeña, el demonio abre la compuerta y deja pasar la molécula al recinto A. De esta forma, el demonio puede bajar la temperatura y disminuir la entropía del gas en el recinto A, violando (aparentemente) la segunda ley de la termodinámica (o violando el teorema H que vimos hoy).
La solución a esta paradoja está relacionada con que el proceso de medir, almacenar, y borrar información del estado de cada molécula requiere realizar trabajo. Los primeros argumentos contra el demonio de Maxwell, de Szilárd Y Brillouin en 1929, consideraban simplemente el trabajo asociado a medir la velocidad de cada molécula, y su costo energético. En este caso, considerando el sistema completo (el gas en ambos recintos y el demonio de Maxwell), la entropía crece y el segundo principio está salvado. Con el tiempo las restricciones en el mínimo de energía necesario para medir el estado de la molécula fueron bajando, y argumentos más modernos contra el demonio de Maxwell usan teoría de la información para estimar el mínimo costo energético necesario para procesar la información adquirida por el demonio. La buena noticia es que aún con las cotas más modernas, el segundo principio no puede ser violado por el demonio de Maxwell, sin importar cuán omnisciente sea (y probablemente Trurl y Clapaucio tampoco puedan violarlo). Los que quieran aprender más sobre este tema pueden leer este artículo: