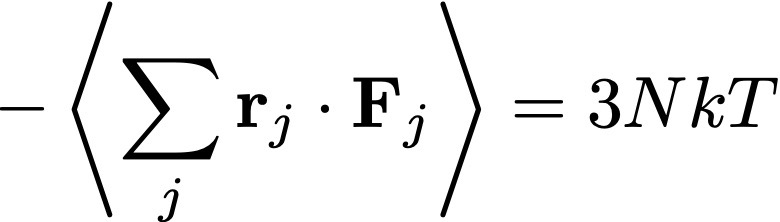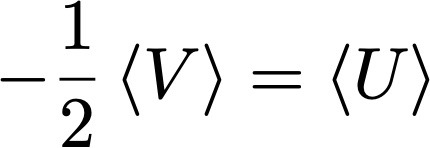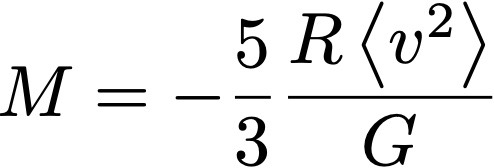Hoy hablaremos sobre cerebros de Boltzmann y su presencia ubicua en la cultura popular. Pueden leer este post mientras escuchan la banda de sonido de Guardianes de la Galaxia (ya se enterarán por qué es relevante en este tema).
El concepto de cerebros de Boltzmann se origina en un paper de Boltzmann de 1895 publicado en Nature, en el que Boltzmann defiende su teoría cinética de diversas críticas. Boltzmann mostró que para un gas diluido, una cantidad que llamó “H” (la entropía de Boltzmann) crecía siempre hasta alcanzar un máximo. Esto llevó a que la gente se pregunte por qué el universo no se encuentra entonces en el estado más desordenado posible. La respuesta posible (y la primer respuesta que dió Boltzmann) es que el universo debe haber comenzado en un estado de muy baja entropía, y actualmente se encuentra evolucionando hacia un estado cada vez más desordenado y con mayor entropía. Pero la segunda respuesta posible (idea de un asistente de Boltzmann, el Dr. Schuetz) es la siguiente:
“Supongamos que todo el universo está, y descansa para siempre, en equilibrio térmico. La probabilidad de que una (solo una) parte del universo se encuentre en un cierto estado, es menor cuanto más lejos esté este estado del equilibrio térmico. Pero esta probabilidad es mayor cuanto mayor es el universo. Si asumimos que el universo es lo suficientemente grande, podemos hacer que la probabilidad de que una parte relativamente pequeña del universo esté en cualquier estado (sin importar el estado de equilibrio) sea tan grande como queramos. También podemos aumentar la probabilidad de que, aunque todo el universo esté en equilibrio térmico, nuestro mundo esté en su estado actual.“
Es decir, de la misma forma que la probabilidad de que todas las partículas de un gas en una habitación estén espontáneamente en una esquina de la habitación es muy baja pero no nula, también existe una probabilidad muy baja (pero no nula) de que en un estado de equilibrio térmico desordenado muy extenso, una fluctuación cree la Tierra con todos nosotros y tal como la vemos ahora. De la misma forma, una fluctuación también podría crear espontáneamente los libros de la Bibioteca de Babel de Borges, o los diálogos de una película de David Lynch.
Si una fluctuación (con muy baja probabilidad) podría hacer esto, ¿por qué no podemos imaginar otros microestados posibles? Como una forma de reducir al absurdo este segundo argumento de Boltzmann, se propuso entonces el concepto de los cerebros de Boltzmann: Una fluctuación podría generar espontáneamente un cerebro completo, flotando en el espacio, con todos sus falsos recuerdos de haber existido previamente. ¿Cómo sabemos que nosotros no somos cerebros de Boltzmann, y que actualmente no estamos decayendo hasta apagarnos en el baño térmico del universo?
El argumento en contra de esta idea fue desarrollado por Sir Arthur Eddington en 1931, y más tarde Richard Feynmann también lo consideró en sus Feynman Lectures. Feynman, luego de explicar que si fueramos una fluctuación del universo, al realizar mediciones en zonas que no observamos antes deberíamos ver un nivel de aleatoriedad diferente al que recordamos, concluye:
“Por lo tanto, concluimos que el universo no es una fluctuación, y que el orden es un recuerdo de las condiciones cuando las cosas comenzaron. Esto no quiere decir que comprendamos la lógica de esto. Por alguna razón el universo tuvo una entropía muy baja inicialmente, y desde entonces la entropía ha aumentado. Así que ese es el camino hacia el futuro. Ese es el origen de toda irreversibilidad, eso es lo que hace que los procesos de crecimiento y decadencia, que nos hace recordar el pasado y no el futuro, nos recuerden las cosas que están más cerca de ese momento en la historia del universo cuando el orden era más alto que ahora, y por qué no podemos recordar cosas donde el desorden es más alto que ahora, al que llamamos el futuro.”
En años más recientes el concepto de cerebros de Boltzmann también se usó para reducir al absurdo algunas ideas en ciertas teorías cosmológicas. Y, extrañamente, apareció repetidas veces en la cultura popular. Como ejemplos, en Guardianes de la Galaxia vol. 2, Ego (el padre de Peter Quill, alias “Star-lord“) es un cerebro gigante en el espacio, creado al inicio de los tiempos:

Y en Futurama existe una raza de cerebros que flotan en el espacio, que fueron creados espontáneamente durante el Big Bang, y que tienen el poder de volver estúpida a la gente (excepto, obviamente, a los que ya son estúpidos):

La idea del asistente de Boltzmann, el Dr. Schuetz, hoy vuelve a tener interés en el estudio de sistemas estadísticos fuera del equilibrio: hoy sabemos que existen evoluciones posibles de estos sistemas en las que la entropía decrece (durante un tiempo acotado) en lugar de crecer. Pero también sabemos que la probabilidad de hallar al sistema evolucionando en esas condiciones es mucho menor que la probabilidad de que el sistema aumente su entropía. Y no solo eso, podemos calcular la probabilidad de que sucedan este tipo de eventos. Existen varias relaciones que permiten calcular la probabilidad de estos eventos; dos de ellas, que fueron verificadas experimentalmente en los últimos años y juegan un rol importante en el estudio de sistemas cuánticos abiertos, materia condensada, y otros sistemas fuera del equilibrio, son la igualdad de Jarzynski y el teorema de fluctuación de Crooks. Básicamente, estas relaciones nos dicen que la probabilidad de encontrar al sistema “desordenándose” en lugar “ordenándose” crece exponencialmente con el cambio de entropía (o de energía libre) en el sistema. Es decir, cuanto más cambie la entropía al evolucionar el sistema hacia el equilibrio, menos probable será encontrar al sistema evolucionando en la dirección contraria. Más adelante volveremos sobre este tema en otro posteo.
Para los interesados en estudio de la conciencia y las neurociencias, en el Departamento de Física el grupo de Enzo Tagliazucchi (@Etagliazucchi) trabaja en temas de conciencia. Y el laboratorio de Gabriel Mindlin (@GaboMindlin) trabaja en temas relacionados con biofísica y el cerebro (¡y sabe cómo leer los sueños de los pájaros!).