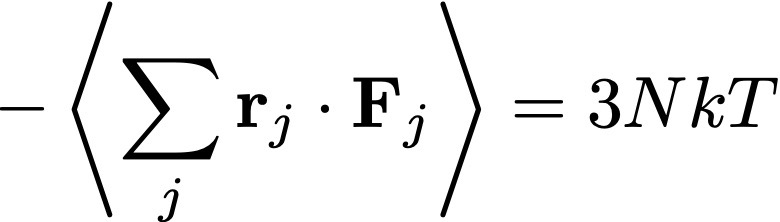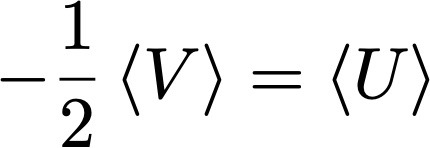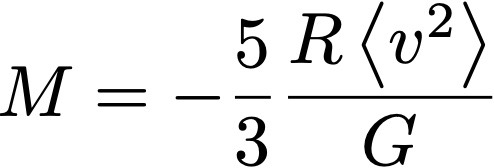Es recomendable que antes de venir a la clase de ayer lean el siguiente [apunte]. A muchos parecerá haberlos inquietado el air Taylor. Despejen ahí sus dudas. Construir desarrollos de Taylor multiplicando desarrollos de Taylor, conservando en cada paso no más que las potencias necesarias, es una habilidad que hay que practicar. Pero tampoco hay que hacer de eso un hábito adamantino: a veces es más fácil calcular derivadas. O sea: ni muy muy, ni tan tan.
Aprovecho también para recomendarles el libro de Dalvit et al., “Problems on statistical mechanics”. Dalvit se licenció aquí en Exactas y a veces se da una vuelta. De este libro provienen muchos problemas de las guías y de los parciales. Ahí pueden encontrar resuelto el problema del gas reticular.
¡Cambio de planes! Considerando las preguntas al final de la clase de hoy, el posteo sobre materia oscura va a venir antes que las aplicaciones económicas. En la clase de hoy vimos el teorema del virial. Este es un teorema muy útil, tanto en la versión de Mecánica Estadística como en su versión de Mecánica Clásica (y probablemente más en el primer caso). Pero también es un teorema que puede ser fácilmente aplicado a situaciones en las que no se cumplen sus hipótesis, para darnos cualquier resultado. Recuerden que las partículas en el sistema deben estar confinadas por el potencial. A continuación les doy dos ejemplos de aplicaciones (aunque no les voy a dar la fórmula para fabricar materia oscura concentrada, y todos sabemos que no es dos partes de quarks plutónicos, una parte de cesio, y una botella de agua).
Comencemos con el gas ideal. Hemos visto que el teorema del virial puede escribirse como
donde las coordenadas r son las posiciones de las partículas, F son las fuerzas sobre cada partícula, N es el número de partículas, y T la temperatura. La suma es sobre todas las partículas. Para un gas ideal, la única fuerza que tenemos está asociada a la presión P. Usando que la fuerza total, sumada sobre todas las partículas, es ∑ r · F = – ∫ r · n P dA (donde n es la normal externa a la pared, y dA el diferencial de superficie), después de hacer algunas cuentas se puede llegar (usando el teorema de Gauss) a que el término de la izquierda es 3PV (con V el volúmen). ¡Por lo que recuperamos la ecuación de estado de un gas ideal: PV = NkT!
Veamos ahora una aplicación más oscura. Consideremos un clúster de N galaxias (es decir, una acumulación de galaxias en el universo), cada una con masa m y con masa total M = Nm. Por ejemplo, podría ser el cúmulo de Coma, un clúster con más de 1000 galaxias identificadas a 321 millones de años luz de la Tierra:
donde U es la energía cinética y V ahora es la energía potencial. Asumiendo que el clúster es esférico, para la fuerza gravitatoria V = -3GM2/(5R), donde G es la constante de gravitación universal, y R el radio del clúster. Por otro lado la energía cinética media es <U> = M<v2>/2. De estas dos relaciones podemos estimar la masa del clúster como
La velocidad cuadrática media de las galaxias en el clúster se puede medir, por ejemplo, por corrimiento Doppler. Y la masa del clúster se puede estimar de forma independiente a esta fórmula a partir de la luminosidad del clúster, usando relaciones bien calibradas en astronomía. Y aquí comienzan los problemas: la fórmula obtenida con el teorema del virial da una masa M mayor que la que se estima con la luminosidad, sugiriendo que falta una fracción de materia que no estamos observando cuando miramos la luminosidad de las galaxias. Este argumento puede ser ampliado para considerar otras formas de energía (por ejemplo, la energía en el campo magnético de las galaxias y del clúster), pero esto no cambia el resultado central: hay una diferencia significativa en la masa estimada por diferentes medios.
Para el caso particular del clúster coma, los primeros estudios que indicaron esta discrepancia entre las masas estimadas de diferentes formas fueron realizados por Fritz Zwicky en 1933. Más tarde, Vera Rubin estudió en detalle la curva de rotación de galaxias individuales, y luego de estudios muy exhaustivos para muchas galaxias, encontró una discrepancia entre la dependencia radial de la velocidad de rotación esperada y la observada, indicando nuevamente una discrepancia entre la masa esperada y la masa observada. Los trabajos de Vera Rubin pusieron en claro la existencia de un problema en cosmología que continúa abierto hasta nuestros días.
Si bien estos no son los únicos argumentos a favor de la existencia de materia oscura, en conjunto con otros resultados nos indican que cerca del 85% de la materia en el universo tiene que ser materia oscura. Y para el caso particular del cúmulo de Coma, estimaciones usando mediciones astronómicas y el teorema del virial indican que cerca del 90% de la materia en el cúmulo es materia oscura.
[Aquí] pueden bajar un breve apunte con la demostración de algo que sólo suele expresarse en palabras y de modo coloquial: la suma sobre todas las energías de la multiplicidad de cada energía multiplicada por el correspondiente factor de Boltzmann es igual a la suma sobre todos los estados, sin restricciones en la energía, del correspondiente factor de Boltzmann. Cuando el sistema está formado por elementos distinguibles y no interactuantes, eso lleva automáticamente a la factorización de la función de partición canónica. En el apunte se trata el caso del sistema de dos niveles, pero la generalización es inmediata.
[Aquí] pueden bajar el problema de los defectos de Frenkel, resuelto con bastante detalle.
La segunda parte de la clase práctica de ayer, más cosas por venir, completa y pasada en limpio, puede bajarse [aquí].
Respecto a las temperaturas negativas, pueden leer el libro de Pathria. En el segundo cuatrimestre de 2015, Pablo Alcain publicó una entrada sobre un recrudecimiento en la discusión acerca de las temperaturas negativas. Pueden leerla [aquí]. Ignoro cómo siguió la historia.
No sé si les dije, pero tenemos un aula en el Campus Virtual. ¿Nadie quiere ser el primero en hacer una consulta por ese medio? Venimos un poco apretados con las clases prácticas y el tiempo de consultas en el aula. Aprovechen el Campus.
Como mencioné en el aula, en esta materia no vamos a demostrar ni a derivar la termodinámica. Esta materia es, en cierto sentido, una materia sobre jerarquías en la naturaleza. No siempre podemos derivar un comportamiento complejo como resultado directo de leyes fundamentales. Muchas, muchísimas veces, al trabajar con sistemas complejos o extensos necesitamos hacer aproximaciones, e introducir conceptos que (aunque tienen vínculos con las leyes fundamentales de la naturaleza) tienen sentido solo en forma aproximada (¡como el calor!). Justamente en este video Feynman dice (en el minuto 0:22): “For example, at one end we have the fundamental laws of physics. Then we invent other terms for concepts which are approximate, which have, we believe, their ultimate explanation in terms of the fundamental laws. For instance, ‘heat’. Heat is supposed to be the jiggling, and the word for a hot thing is just the word for a mass of atoms which are jiggling.” (“Por ejemplo, en un extremo tenemos las leyes fundamentales de la física. Luego inventamos otros términos para conceptos que son aproximados, que, creemos, tienen su explicación última en términos de las leyes fundamentales. Por ejemplo, el “calor”. Se supone que el calor es la vibración, y la palabra para algo caliente es solo la palabra que usamos para una masa de átomos que se sacuden.”).
Noten que Feynman no intenta convencernos de que hay una expresión formal y correcta para el calor en términos de leyes o magnitudes físicas fundamentales. Nos dice que el calor es un concepto aproximado para describir ciertos fenómenos en una escala macroscópica. Muchos conceptos en termodinámica son de este tipo: algunos podremos formalizarlos, para otros necesitaremos muchas aproximaciones. Y la descripción microscópica que construiremos será compatible (por diseño y construcción) con la termodinámica, porque si la violase construiríamos otra teoría microscópica. El enfoque de esta materia nos puede ayudar a entender ciertos sistemas físicos de otra forma, pero no se confundan y piensen que porque una teoría se deriva con más cuentas y trabajo es necesariamente mejor. Porque es imposible unir las dos descripciones (la macroscópica y la microscópica) sin hacer muchas aproximaciones en el medio, de forma tal que más que ser la segunda descripción más perfecta o formal, no podría existir si no comprendiésemos muy bien la primera. En cierta forma, esta materia cumple al pie de la letra una frase que probablemente nunca fue dicha por Groucho Marx: “Éstos son mis principios, y si no le gustan, tengo otros“.
Sobre este punto, en el video Feynman dice algo muy interesante, y que va contra la concepción simplista de la física que imagina que entender un fenómeno se reduce siempre a reducirlo a las leyes o principios fundamentales que están detrás. En el video Feynman continúa hablando de sistemas cada vez mas complejos, y aproximaciones cada vez mayores. Y en el minuto 2:52 se pregunta: “Which end is nearer to the ultimate creator, if I may use a religious metaphor? Which end is nearer to God? Beauty and hope, or the fundamental laws? I think that the right way, of course, is to say that the whole structural interconnection of the thing is what we have to look at. [...] And so I do not think either end is nearer to God. To stand at either end, and to walk off that end of the pier only, hoping that out in that direction is the complete understanding, is a mistake.” (“¿Qué extremo está más cerca del creador final, si puedo usar una metáfora religiosa? ¿Qué extremo está más cerca de Dios? ¿La belleza y la esperanza, o las leyes fundamentales? Creo que la respuesta correcta, por supuesto, es decir que lo que debemos mirar es la interconexión completa de las cosas. [...] Y entonces no creo que ninguno de los dos extremos esté más cerca de Dios. Pararse en cualquier extremo y caminar solo por ese extremo del muelle, esperando que partiendo desde ese punto encontraremos el entendimiento completo, es un error.”).
En términos más contemporáneos, los sistemas físicos extensos son como los ogros. Y los ogros son como las cebollas. ¿Apestan? ¡No! ¿Te hacen llorar? ¡No! ¿Si los dejás al sol se vuelven marrones y les crecen pelitos blancos? ¡Tampoco! Las cebollas tienen capas. Los ogros tiene capas. Y los sistemas físicos extensos tienen capas, como los ogros y las cebollas.
Y como los ogros, los sistemas físicos extensos no pueden comprenderse si solo miramos las capas más externas, o si solo miramos las capas centrales. Es la capacidad de mirar el conjunto lo que hace que dejemos de ser tan burros y podamos entender a los ogros.
En esta materia nos interesan los sistemas extensos, para los que estamos haciendo (y vamos a tener que hacer) muchas aproximaciones. La elección de qué aproximaciones son razonables, y cuales no, serán el resultado de observar la naturaleza. No espero que respondamos la pregunta de Feynmann sobre qué extremo está más cerca de la verdad última, pero sí espero que podamos encontrar interés en estudiar ambos extremos de las jerarquías de los sistemas físicos. Y que aprendamos que los sistemas físicos complejos muchas veces no pueden ser reducidos a ecuaciones en términos de las leyes fundamentales de la física. Pero que, sin embargo, lo que aprendimos hasta ahora sobre las leyes fundamentales y sobre sistemas sencillos nos pueden ayudar a comprender mejor a los sistemas complejos. Porque no siempre podemos obtener lo que queremos, pero si lo intentamos, podemos encontrar lo que necesitamos.
De yapa, otro video de Feynman hablando de ciencia, el calor, la temperatura, y muchas cosas más:
[Aquí] pueden bajar la nueva transmigración de la guía de ensambles. Este cuatrimestre, ocupa el tercer lugar. Es la guía más importante antes del primer parcial.
El problema de la clase práctica de ayer puede bajarse, pasado en limpio, [aquí]. La semana que viene empezamos con la Guía 3, que es la guía. Hasta aquí fue todo preparativos.
A propósito del problema 16 de la Guía 2, de los dos jugadores que tiran una moneda, alguien me preguntó ayer sobre el problema de las series de penales. Para decidir quién patea primero se tira una moneda. Pero lo que viene después depende más de la psicología que del cálculo de probabilidades. [Aquí] pueden leer una nota de Paenza muy informativa.
Recuerden que hasta el 7 tienen tiempo de inscribirse en la materia.
“Este pensador observó que todos los libros, por diversos que sean, constan de elementos iguales: el espacio, el punto, la coma, las veintidós letras del alfabeto. También alegó un hecho que todos los viajeros han confirmado: No hay en la vasta Biblioteca, dos libros idénticos. De esas premisas incontrovertibles dedujo que la Biblioteca es total y que sus anaqueles registran todas las posibles combinaciones de los veintitantos símbolos ortográficos (número, aunque vastísimo, no infinito) o sea todo lo que es dable expresar: en todos los idiomas. Todo: la historia minuciosa del porvenir, las autobiografías de los arcángeles, el catálogo fiel de la Biblioteca, miles y miles de catálogos falsos, la demostración de la falacia de esos catálogos, la demostración de la falacia del catálogo verdadero, el evangelio gnóstico de Basilides, el comentario de ese evangelio, el comentario del comentario de ese evangelio, la relación verídica de tu muerte, la versión de cada libro a todas las lenguas, las interpolaciones de cada libro en todos los libros, el tratado que Beda pudo escribir (y no escribió) sobre la mitología de los sajones, los libros perdidos de Tácito.”
Jorge Luis Borges, La Biblioteca de Babel (1941).
¿De cuántas formas pueden reordenarse los veintitantos símbolos ortográficos de la Biblioteca de Babel? ¿De cuántas formas puede Christopher Nolan reordenar el argumento de sus películas para hacer una película nueva? (de ser posible, que todavía se entienda). ¿Y cuanta información quedará en la película más arrevesada que Christopher Nolan pueda dirigir? Como suele ocurrir, los Simpsons se preguntaron todo esto antes (¡pero no antes que Borges o que Claude Shannon!):
¿Cuál es la relación entre entropía e información? En 1949, ocho años después que Borges publicase La Biblioteca de Babel, Claude Shannon publicó un trabajo en el que introdujo su famoso concepto de entropía de la información,
S = – Σ pi log pi.
En ese trabajo, aunque presentó una serie de teoremas con motivaciones plausibles, Shannon acepta que su principal motivación para usar una definición de este tipo, y en particular la función logaritmo, tiene que ver con que es práctica para lidiar con magnitudes medidas que pueden variar en varios órdenes de magnitud, con que vuelve ciertas operaciones con números grandes más fáciles de manejar, y con resultados previos en mecánica estadística como las definiciones de entropía de Boltzmann y de Gibbs. Shannon usó log2, pero nosotros usamos el logaritmo natural porque es más natural para nuestra materia. En clase vimos cómo esta definición se relaciona con nociones de desorden o de interteza, y que para sucesos equiprobables se reduce a S = log(N), donde N es el número de sucesos posibles. Pero ¿cómo se relaciona esto con la noción de información?
Llamativamente, Borges se adelantó en su Biblioteca de Babel a esta pregunta. En otra parte del cuento escribe:
“El número de símbolos ortográficos es veinticinco. Esa comprobación permitió, hace trescientos años, formular una teoría general de la Biblioteca y resolver satisfactoriamente el problema que ninguna conjetura había descifrado: la naturaleza informe y caótica de casi todos los libros. Uno, que mi padre vio en un hexágono del circuito quince noventa y cuatro, constaba de las letras MCV perversamente repetidas desde el renglón primero hasta el último. Otro (muy consultado en esta zona) es un mero laberinto de letras, pero la página penúltima dice «Oh tiempo tus pirámides».”
Imaginemos, como Borges, un conjunto de símbolos ortográficos formado por 22 letras del alfabeto, mas el punto, la coma y el espacio (que marcaremos como “_”):
El primer mono (M1) aprieta la letra A todas las veces: “AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA”.
El segundo mono (M2) aprieta solo letras con equiprobabilidad, sin usar puntuación o espacios: “AYZTMOICPQERVILVVLMODNBEKSDEHGAHGALMKEYC”
El tercer mono (M3) aprieta cualquiera de las 25 teclas con equiprobabilidad: “DH, EKHVOZ . EZVIASC B PIM,YICAK DELA.ALSFBZOQNY E”.
El cuarto mono (M4) aprieta cualquier tecla con su probabilidad de uso en el español (por ejemplo, el espacio tiene una probabilidad de ocurrencia de ≈ 0.17, la letra “A” de ≈ 0.10, la “E” de ≈ 0.11, etc.): “EOS RILND . QNL PAE A ARDTEOS DCMAEE AMA”.
El quinto mono (M5) tiene un vocabulario de 10 palabras, y usa las reglas de espaciado y puntuación del español. Su vocabulario es: CASA, PEPE, TUS, PESCA, EN, PIRAMIDES, DOS, OH, PARA y TIEMPO. Usando solo esas palabras al azar, y el punto, la coma y el espacio, escribe: “DOS PESCA. TUS CASA PEPE, OH TIEMPO TUS PIRAMIDES.”
¿Cuánta información hay en cada mensaje? Para contestar esto, preguntémonos para qué emisor es más difícil predecir la ocurrencia de la siguiente letra, si nos llegasen sus mensajes de a una letra por vez (por ejemplo, por un telégrafo). En el primer caso, una vez que reconocimos el patrón, es fácil saber que la siguiente letra será una A. Cada nueva A no agrega entonces más información que la que ya teníamos (¡ya sabíamos que nos llegaría una A!). Es fácil también ver que el caso más difícil para predecir la ocurrencia de una nueva letra corresponde al del mono M3. Por otro lado, el mensaje de M5 parece más complicado, pero luego de recibir las letras “PES”, sabemos que solo pueden estar seguidas por “CA”. La entropía de Shannon mide esta noción de información, basada en la idea de que cuanto más difícil sea predecir la siguiente letra, más información nos aporta conocerla. Calculemos la entropía de cada emisor:
S1 = ln 1 = 0
S2 = ln 22 ≈ 3.091
S3 = ln 25 ≈ 3.219
S4 = -Σ pi log pi ≈ 2.766
La entropía S5 es más difícil de calcular, pero es menor a S4 y mayor a S1.
Hay otra forma interesante de pensar cuánta información genera el emisor, y es pensar cuánto podemos comprimir el mensaje que nos envía el emisor sin perder información. Para el primer mono nos alcanza con decir que envió 50 “A”. El mensaje de M5 lo podemos comprimir como “D PES. TU C PEP, O TI TU PIR.” (ya que “D” solo puede ser seguido por “OS”, “PES” por “CA”, “TU” por “S”, etc.). En el mensaje de M3 no podemos sacar nada sin perder información. Un teorema famoso de Shannon nos dice que (para mensajes muy largos) la cota máxima a cuánto podemos comprimir el mensaje de un emisor sin perder información está relacionada con su entropía.
Los que quieran saber más pueden leer el paper original de Shannon:
Me imagino que todos quieren ser millonarios. ¡Pero seguro nunca se imaginaron que esta materia era la forma de alcanzar sus deseos! Salvo, obviamente, que hayan visto The hangover (2009), o películas un poco más serias como Rain Man (1988) y 21 (2008) (ambas basadas, con diversas libertades narrativas, en historias reales). En la última teórica vimos probabilidades. Las herramientas del curso se pueden usar para ganar en juegos de azar (¡o mejor aún, para evitarlos!), y para ilustrar cómo les cuento dos historias.
La primer historia es la del método para ganar en la ruleta de Edward Thorp (también creador de métodos para contar cartas en el blackjack) y Claude Shannon (el mismo Shannon de la entropía que veremos repetidas veces en la materia). Todos los juegos de azar en los casinos tienen esperanza negativa: si siguen jugando, a la larga solo pueden perder. En el caso de la ruleta, esto está relacionado con que un pleno (acertar a un número) paga 35 veces la apuesta, pero la probabilidad de acertar el número es 1/37 (pues la ruleta tiene 36 números más el cero). Así, en promedio, cada vez que apuestan pierden. El desafío es convertir la esperanza en positiva, es decir, saber con probabilidad mayor a 1/35 qué número va a salir. En los siguientes artículos Edward Thorp explica en detalle diversos métodos para ganar en la ruleta:
Los que quieran mas información sobre juegos de azar (y las siguientes entregas de estos artículos) pueden mirar la página web de Edward Thorp.
Básicamente existen tres tipos de métodos para la ruleta: (1) métodos matemáticos, (2) métodos basados en desperfectos de la ruleta, y (3) métodos predictivos basados en la física de la ruleta. Los primeros no son viables, ya que como mencioné arriba, los juegos de casino están diseñados para tener esperanza negativa. Para ser más claro: todo método que les cuenten basado solo en la matemática o la estadística o es mentira, o está explícitamente prohibido en las reglas del juego que usan los casinos. Al segundo método vamos a volver en un rato. El tercer camino es el que eligieron Thorp y Shannon.
En 1960 Thorp y Shannon usaron el hecho de que en los casinos se puede seguir apostando mientras la ruleta gira (y hasta que el crupier grita “¡No va más!”) para crear un algoritmo que basado en la velocidad de rotación de la ruleta, la velocidad de la bola, y su posición inicial aproximada (estimadas contando solo con inspección visual el número de vueltas que la ruleta y la bola dan en un período corto de tiempo), predice estadísticamente en qué octante de la ruleta puede caer la bola. En espíritu (aunque no en los detalles) esto es parecido a lo que vimos en el problema del camino al azar: no podemos saber dónde terminará la bola, pero nos alcanza con conocer la zona más probable de la ruleta en la que la bola puede terminar. Con esta información extra, la esperanza se vuelve positiva para el apostador. Pueden encontrar un artículo de divulgación con esta historia aquí:
Para realizar predicciones rápidas en el casino, Thorp y Shannon armaron una computadora pequeña, del tamaño de un atado de cigarrillos, que se llevaba con una faja en la cintura y se conectaba al zapato para ingresar los datos pisando fuerte o moviendo los dedos del pie. La siguiente foto muestra la pequeña computadora de Thorp y Shannon (la que se llevaba en la cintura):
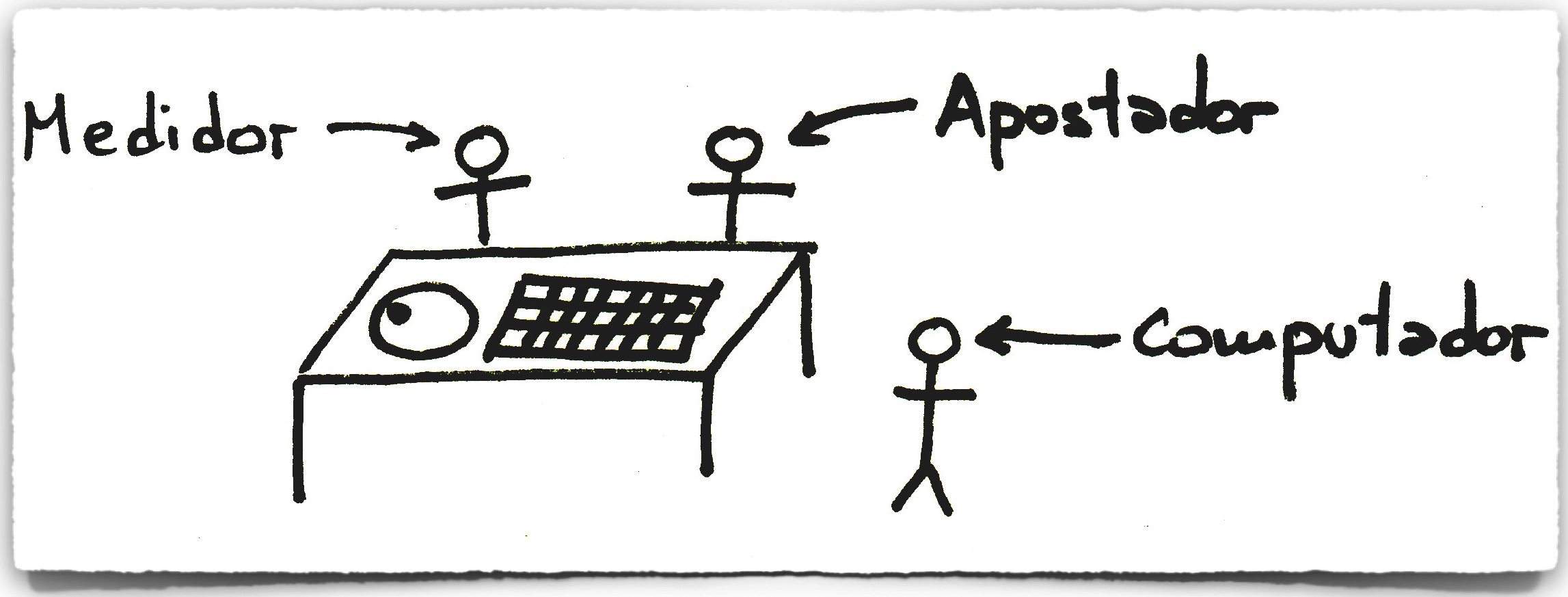
Otra persona (el apostador) usaba un pequeño receptor y un auricular para obtener la predicción y realizar rápidamente una apuesta. En la práctica, y para evitar ser detectados usaban a tres personas: una que medía, otra que llevaba la computadora, y el tercero que realizaba la apuesta, todos conectados por un sistema de radio:
¡Lo mas interesante es que el método funciona! Thorp y Shannon lo usaron con cierto éxito en Las Vegas. Una década más tarde un grupo de estudiantes de California perfeccionaría el sistema reduciendo aún más las computadoras y escondiéndolas completamente en zapatos (aquí pueden ver una imagen de las computadoras y encontrar algunos detalles sobre cómo funcionaban; el apostador ingresaba el período de rotación de la ruleta y el de la bola apretando un pulsador con el dedo del pie, y en otro zapato otra computadora devolvía la predicción del octante en el que caería la bola con una vibración). Todo esto además terminó siendo usado para el guión de un episodio de la serie original de Misión Imposible (1966), con un título insuperable:
La segunda historia tiene que ver con el segundo método para ganar en la ruleta, basado en desperfectos de la ruleta, e involucra a un estudiante de doctorado de Richard Feynman. Alrededor de 1940, Albert Hibbs y Roy Walford acumularon datos de jugadas en casinos de Reno y Las Vegas, para identificar algún pequeño bias o desperfecto en las ruedas de ruleta que favoreciera estadísticamente a ciertos números. Usando los datos estadísticos obtenidos para cada ruleta, Hibbs y Walford ganaron 8300 dólares en un día (las ruletas actuales no tienen este nivel de imperfección, por lo que el método ya no es aplicable hoy). Pueden leer una historia sobre Hibbs y Walford aquí:
Espero haberlos convencido, con estas historias, de que lo más conveniente es no apostar (salvo que uno esté dispuesto a esconder una computadora en un zapato). Para mostrar que más de 4000 físicos llegaron a la misma conclusión, les dejo un link a la famosa historia de la convención de físicos en Las Vegas que dió origen a la frase “They each brought one shirt and a ten-dollar bill, and changed neither”:
Ahora que mejoran las relaciones con China, todos deberían estar leyendo la novela clásica china El sueño del pabellón rojo. El texto anterior lo copié de mi propio ejemplar, no recuerdo si del primer o del segundo tomo. Pregunta: sin espiar la Wikipedia, ¿pueden decir cuántos personajes principales tiene la novela? ¿Cuál es el número de personajes que maximiza la probabilidad de que ocurran las cosas que se nos dicen?
Hasta la medianoche del 7 de abril tienen tiempo de reconsiderar su inscripción a Teórica 3.